我們是如何理解由視覺接受到的場景與畫面呢?因為雙眼立體視覺的關係,我們能輕易透過深度感知,來區分遠近背景與物件,個別物件再去理解其位置、描述,甚至是物件之間的關係,我們對於場景的理解是「物件導向」的,我們先有了各種物件的概念,再去感知它們出現在哪?它們有怎樣的描述?它們有什麼關係?腦袋如何生成一幅「心智圖畫」來反應世界?
我們觀測到現實,並且對於其中一些隱藏變量進行估計,例如物件數量、位置、描述等等,然後在腦海中重新生成一幅「心智圖畫」來代表所看到的現實,如果所估計的變量正確,我們期待所生成的心智圖畫會跟現實很像;本篇我們使用 Pyro 來實作一個生成模型,模型生成個別物件的資訊與位置,然後透過可微分渲染器來產生影像,最後使用VI老方法來訓練生成模型與估計模型。
本篇主要參考了 Refernece 中的第一篇,為 AAAI 2019 的論文,簡化了模型與實驗的設定,並且用 Pyro 機率語言更簡明的實作出來(原始論文的code是tf 1.x寫的,很難讀呀…)
可微分渲染器
假設我們有個物件要擺到畫布上,我們可以透過 Indexing,例如array[i,j] = obj,但 Pytorch indexing 是無法傳遞梯度的,例子中的 i,j 是無法微分的,所以我們沒辦法去有梯度改變i,j,把物件移動到我們想要的地方,這可是大問題呀!沒有可微分的渲染器,就沒辦法生成影像,所以可微分程式是很重要的呀!(關於可微分程式之後再跟大家分享討論)
我們希望擺的位置是可以微分的,該怎麼做呢?我們可以用 Spatial transformer networks (STN) 來將物件放到畫布上,並且整個過程是可以微分的,但這裡不詳述STN的原理
1 | def render(obj_param,logit): |
obj_param 代表物件的座標參數,logit 代表物件出現的機率,透過 obj_to_image_param 做參數的轉換,把物件參數轉換到畫布參數,並放到 theta 中用 affine_grid 與 grid_sample 函數來把物件放到畫布上
1 | out , img_ = render(torch.zeros(2,4,4,2,2),torch.ones(2,4,4,2,1)) |
借鏡 Yolo 模型,把影像分成4*4的方格,每個方格內可以有2個物件,每個物件有x,y偏移座標與出現機率,測試一下渲染器,每個方格內有2個白色物件,且偏移座標為0(所以在正中間重疊),出現機率都是1

Yolo-like generative model
模型根據定義的維度,每個物件可能出現的方格內抽樣物件的座標與機率,用Pyro來表示相當簡潔,plate代表每個維度間互相獨立,抽樣出來的參數在送給宣染器來產生抽樣出影像
1 | def model(obs): |
從模型直接做抽樣,物件的深淺反映可能出現的機率


Guide
接著來做估計,可以先嘗試看看點估計,看看VI方法能不能估計出想要的隱藏變量
1 | guide = AutoDelta(pyro.poutine.block(model, expose=["obj_param","obj_logit"])) |
或是用Amortized inference,引入一個估計模型訓練神經網路直接去預測隱藏變量
1 | encoder = nn.Sequential(nn.Conv2d(1,16,3,2,1), |
Inference
當 Model 與 Guide 都定義好後,就用VI方法來訓練囉!(比自己從頭寫,方便多了呀!)
1 | pyro.clear_param_store() |
Result
把訓練過後的 guide 所估計的物件框畫在訓練資料上來看看,可以看到還蠻不錯的
1 | idx = 0 |

目前我們是直接用模型來生成訓練資料,生成的資料完全符合模型假設,當然比較容易訓練,我們來換個生成訓練資料的方式,用均勻分布的方式抽樣物件數量與位置,還有把物件換成圓形
1 | def draw_sprites(): |


經過訓練後結果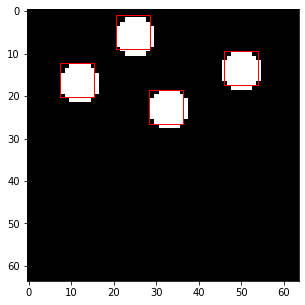
結語
本篇介紹了一個 Unsupervised object detection 的方法,我們定義了一個影像生成的過程與模型,我們假設所看到的影像背後都有一些隱藏的生成參數,我們如果能很好的估計出來,就能也生成出接近一樣的影像(影像還原誤差),所以我們可以透過著個方式,來評斷估計的隱變量好壞,進而去訓練估計模型預測隱變量,物件座標也只是其中的一種隱變量,還有物件大小、類別、甚至光影都可以是,都可以套用這個框架去延伸,當然本篇只是淺嚐而止,只是一個概念驗證,離能真的用在真實影像上的物件偵測還非常的遠,但多少能換個思路去理解生成模型或是非監督式學習能怎樣扮演其他學習任務的基石。
下篇已經大概知道要寫什麼,但還沒寫之前都不敢說,敬請期待!