Hinton 大神於2017年提出 Dynamic Routing Between Capsules,探討了CNN的缺陷並提出Capsules概念,2018的 Matrix capsules with EM routing 改進了其中 routing 機制,到2019年這篇 Stacked Capsule Autoencoders 算是這個系列的集大成,概念脈絡更為清楚,大神也在 AAAI 2020 給了一個關於本篇論文的演講,他還特別提到說請大家忘記前兩篇論文,這篇才是對的!足見這一篇論文的重要性
本篇文章不是詳細解讀 Stacked Capsule Autoencoders (SCAE)的文章,如果想要深入了解這篇論文,推薦看第一作者寫的部落格文章與搭配論文服用,本篇文章是想從生成模型的角度去重新理解與實作 capsule 這個概念,建議先閱讀過之前的文章,用生成模型概念來解決物件偵測問題跟本論文也有很相似的概念,另外很有趣的是,上述提到第一作者的部落格文章中,有提到為何不用生成模型的方式來實現 SCAE,這也啟發我一些思考與後續探討,故寫成文章與大家討論
Stacked Capsule Autoencoders
Capsules
在進入模型架構前,想先來談談 capsule 這個概念,上述提到的作者部落格文章中有定義什麼是 capsule
We define a capsule as a specialized part of a model that describes an abstract entity, e.g. a part or an object.
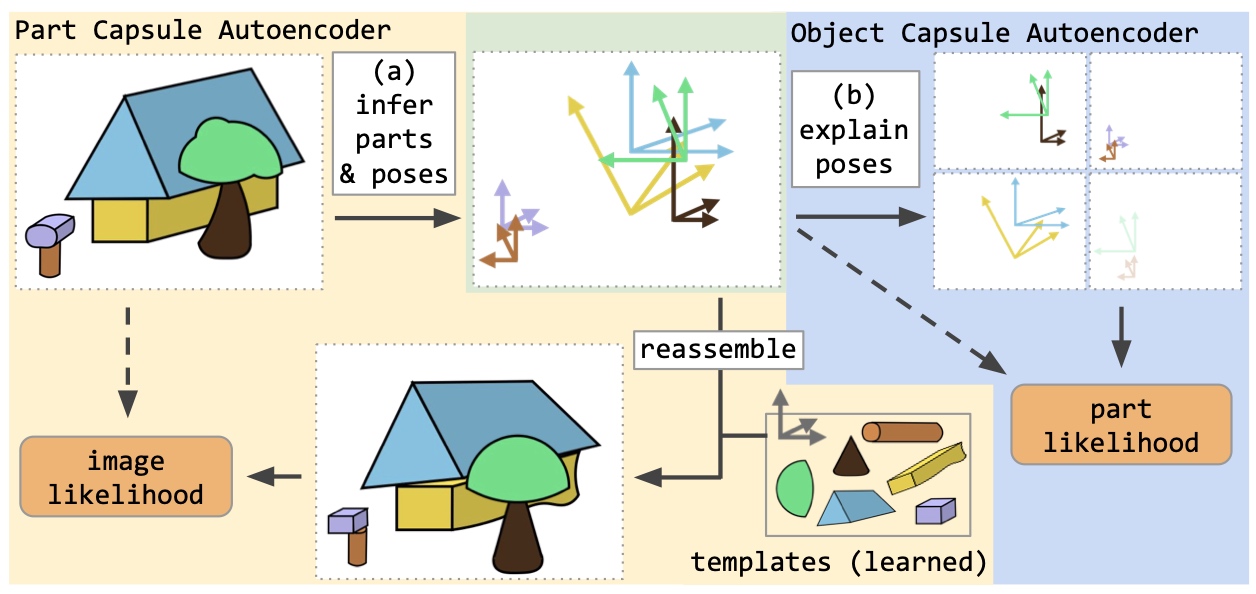
形象上的描述就是積木與組合,一個高階概念是由多個低階概念所組成,低階的概念就像是積木一樣,我們可以組合出更複雜的物件,也就是高階概念,組合的過程中,我們要去選取適當的積木,還要去旋轉積木的姿態來組合;從視覺辨識物件的過程來看,我們看到一個影像並想要知道那是什麼,先去辨識影像用了哪些積木,那些積木分別姿態是什麼,這比起直接去辨識整個物件,積木多半更為簡單,更容易辨識出來,然後我們將有用到的積木搜集起來,看看用這些積木能組合出什麼,透過訓練我們希望特定積木的集合,會對應到特定的物件類別,看到收集到的積木就知道這大概只能組合出哪些東西,我們就能知道這個影像是什麼,這樣組合過程可以一直下去,從只有幾個積木,但到最後可以組合出非常複雜的影像或概念
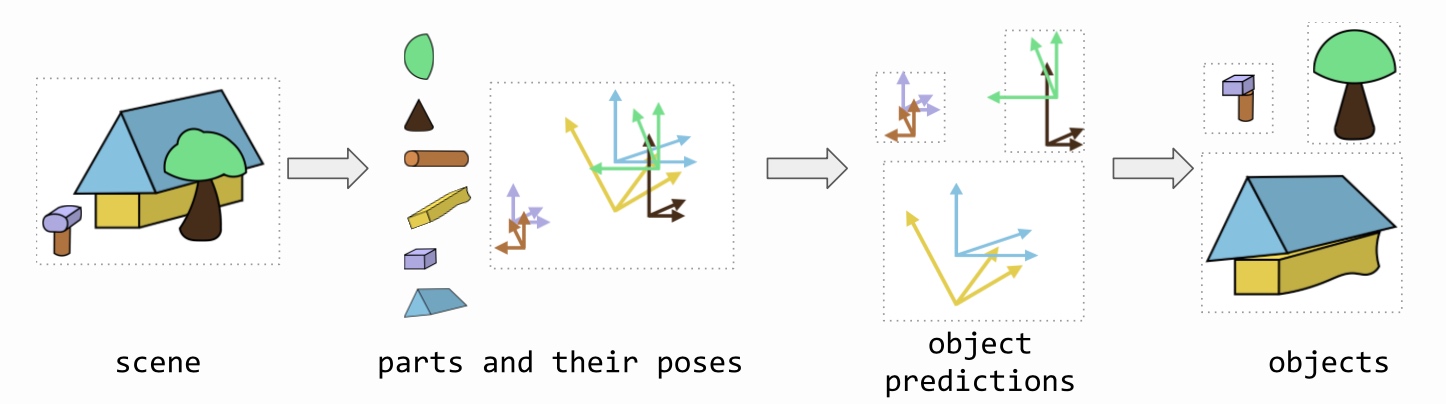
概覽一下整個模型,輸入影像後找出使用的積木與姿態,再來根據收集到的積木來看能組合出哪些物件
Part Capsule Autoencoder
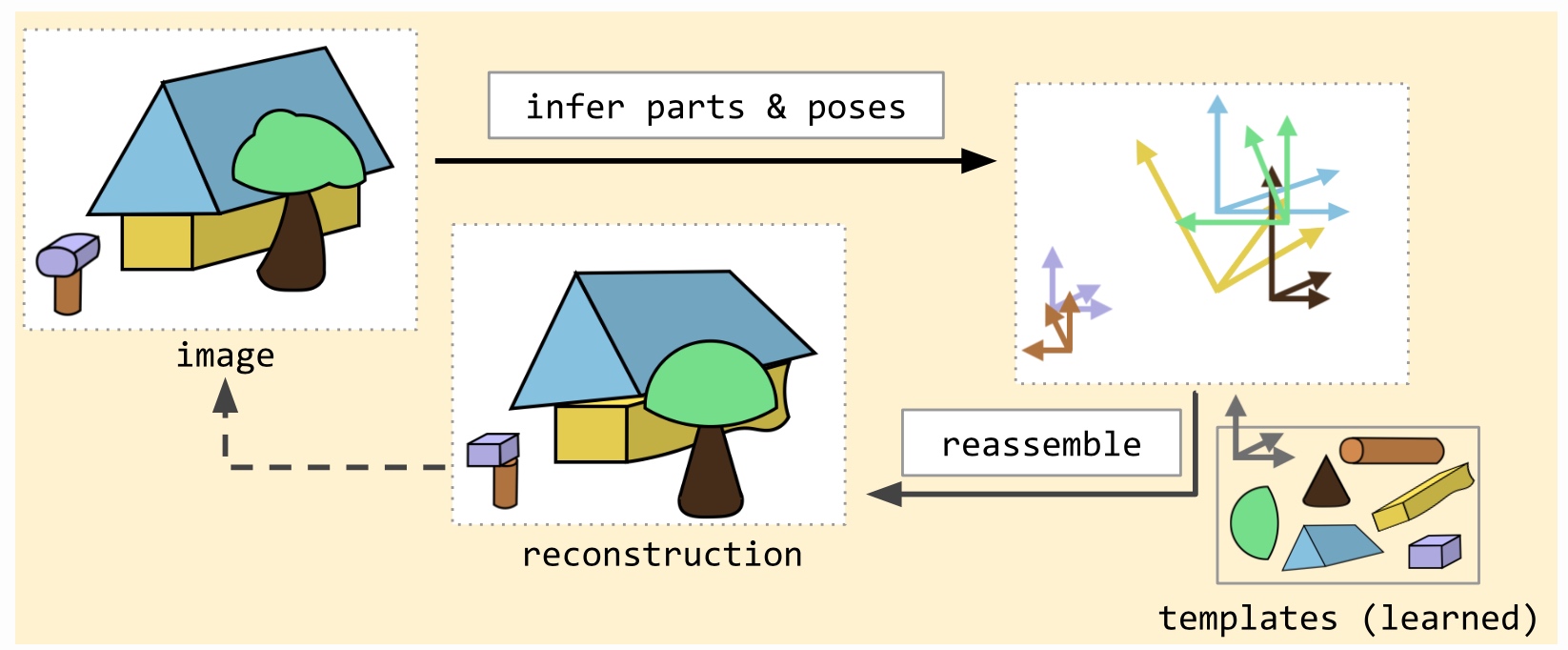
第一部分訓練模型去學習積木與估計姿態,姿態包含位置、大小、旋轉,積木是指有多個小張影像,例如輸入影像是28x28,積木影像為11x11,輸入影像後模型會輸出每個積木影像的使用機率與姿態,然後還原輸入影像來訓練模型與積木影像
Object Capsule Autoencoder
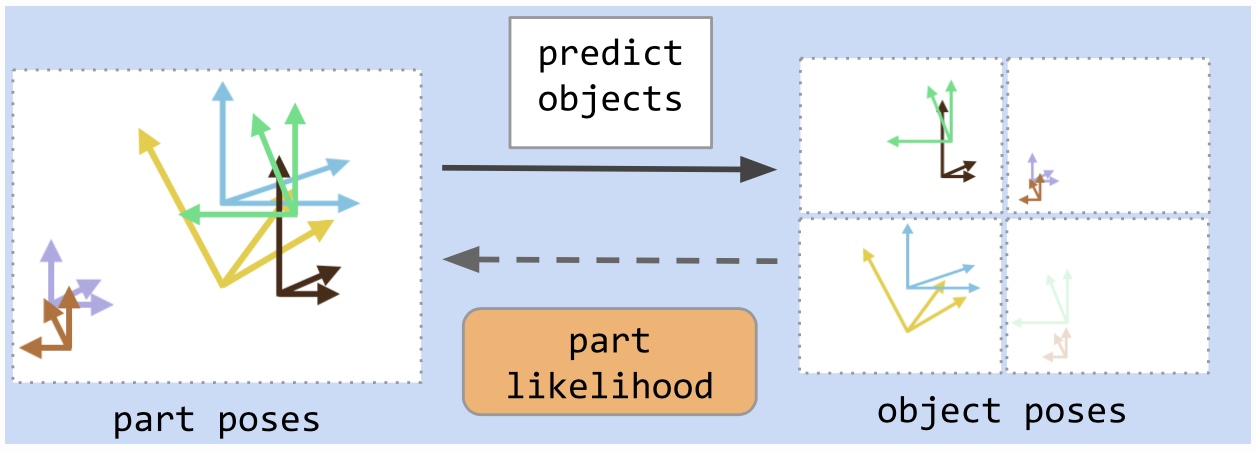
第二部分為把積木聚合成物件,使用 EM 的迭代估計的方式(類似 Kmean),來找出中心點,且加入 sparsity regularization 讓積木只集中在某幾個物件上
Implementation
接著我們來嘗試實作 Part Capsule Autoencoder,這個部分與之前實作非監督的物件偵測概念非常類似,也同樣使用 Pyro 來實作,生成模型必須使用積木去組合出影像,積木的使用機率與姿態就是隱藏變量,我們訓練另一個模型去估計這些變量
Model
1 | def model(self,obs): |
大致看一下生成模型定義,詳細的函數可以參考我的實作,templates 就是積木,這裡用了16個11x11的影像,並且也是可以學習的,接著每個 templates 都去抽樣出姿態與使用機率,最後用可微分渲染器去生成影像,我們直接生成影像來看看

Result
模型在 MNIST 訓練資料集上訓練,得到一些不錯的結果,下圖左邊是訓練資料,右邊是還原影像
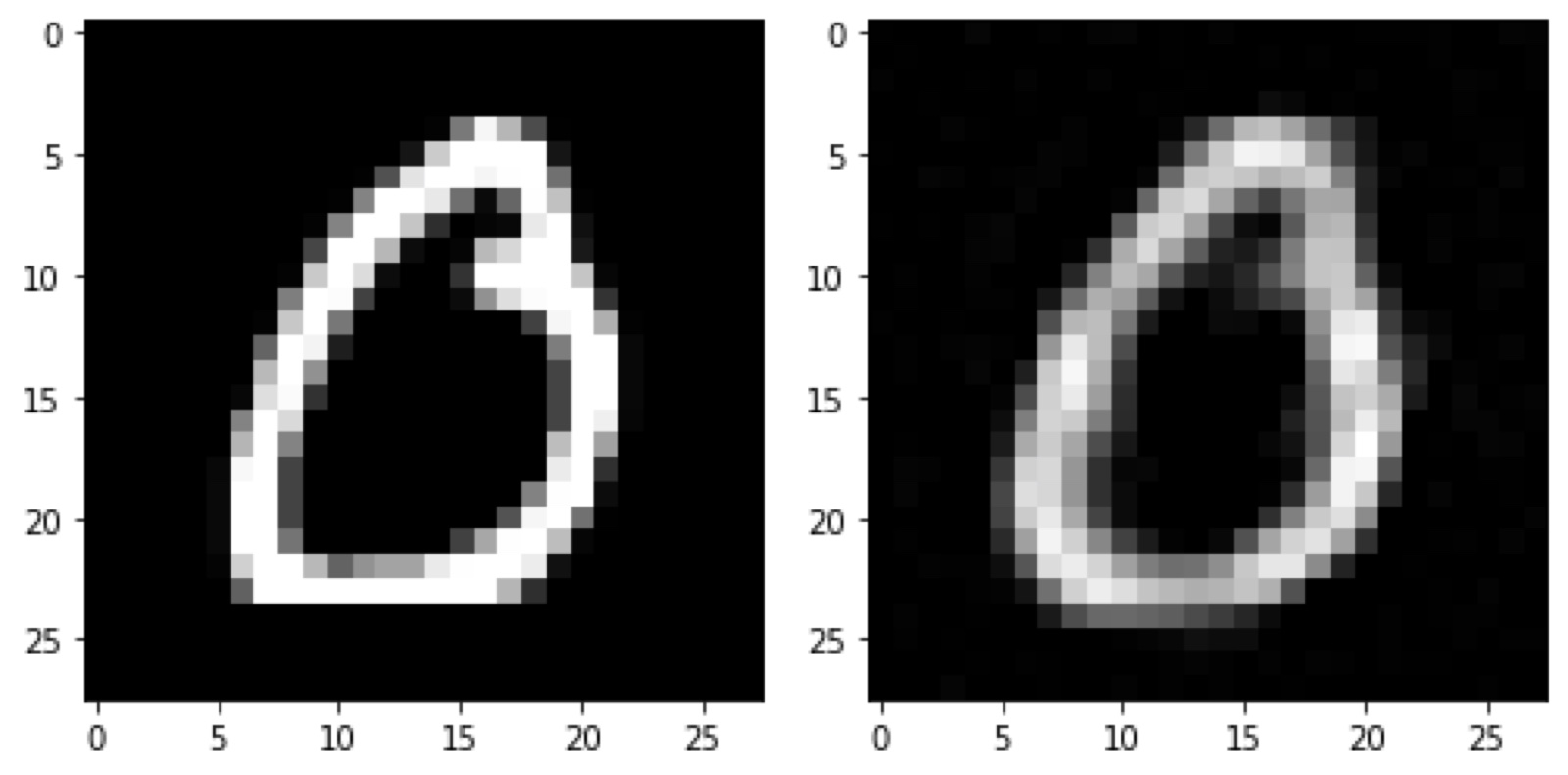
我們來看看模型學到的積木長怎樣,左邊是論文給出的模型訓練在 MNIST 學到的結果,右邊則是實作得到的,雖然與論文設定不完全相同,但顯示模型有學到一些有用的積木

右邊是依照使用機率排序的 templates,左邊是將使用機率高於0.5的積木來組合成影像,顯示模型是會去選擇重要的積木來組成,不是全部都用上

在測試資料集上,也有不錯的效果,右邊是測試資料,左邊是還原影像
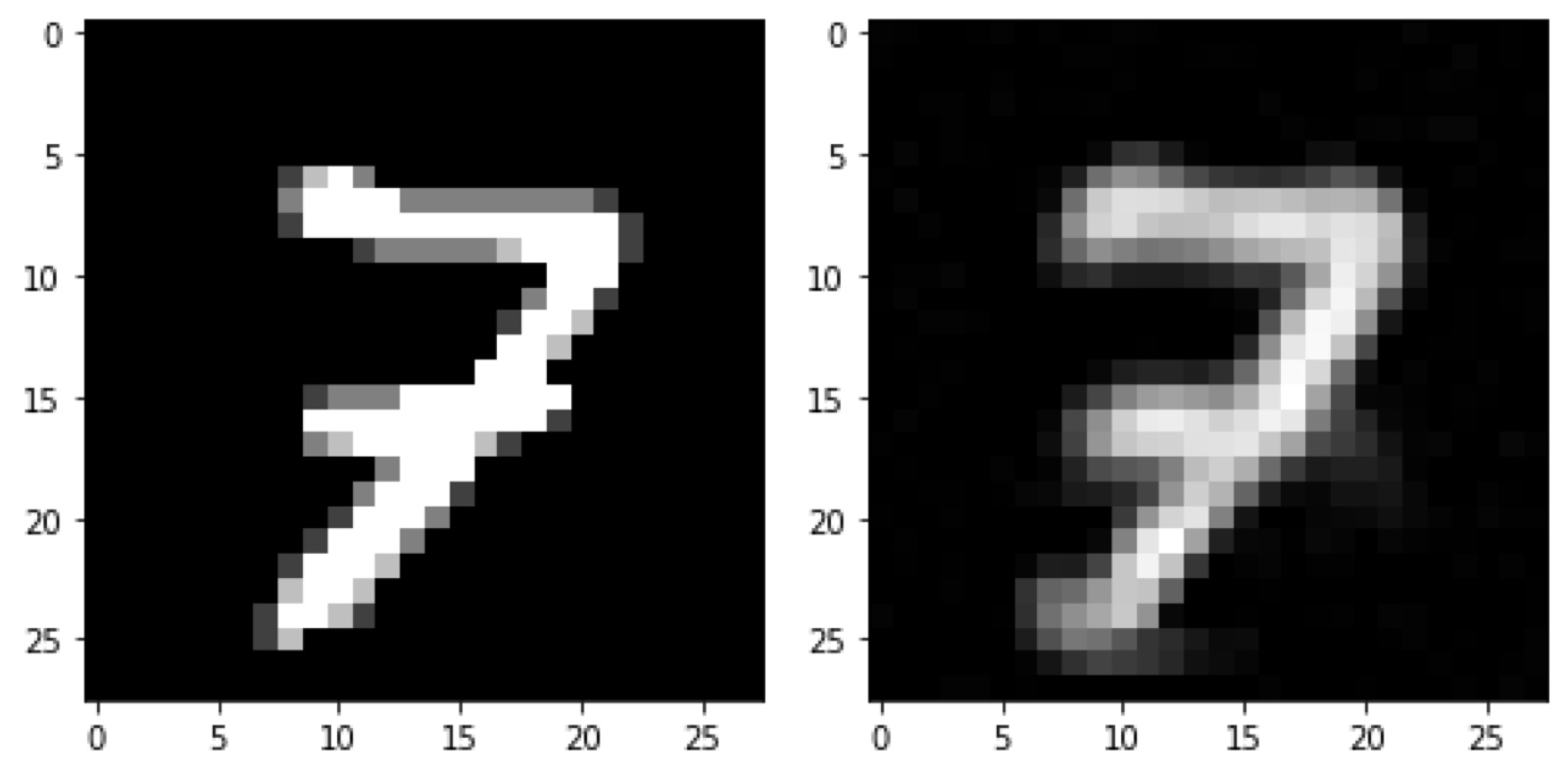
選取機率高的積木來組成

結語
我的實作版本與官方實作是不同的,雖然 capsules 概念上是相同的,不同點在於 SCAE 官方實作把 capsules 概念放到估計模型上,而我的版本則放到生成模型裡
- 官方實作:capsules encoder + decoder
- 我的實作:encoder + capsules generator
作者認為 SCAE 當然可以用生成模型來實作,像是我們很熟悉的VI框架一樣,定義一個生成模型與估計模型,用估計模型去近似隱藏變量,但我們往往都是把一些結構先驗知識放到生成模型去,我們會去假設變量之間關係與結構等等,再用任意的模型去當估計模型,但這樣的缺點就是隱變量後驗分佈往往很複雜,估計模型不容易很好近似,估計模型應該需要更多的額外知識來輔助,如果估計模型裡沒有 capsules 架構是無法學到 capsule-like representations 的
我的版本則是照生成模型的概念去實現,如果解碼器太過強大,它是可以忽略編碼器給的訊息,依然可以把資料還原得很好,所以就算編碼器是含有有先驗結構的,也可能無法學到有用資訊,所以我將先驗結構放在生成模型,用估計模型來近似,希望可以得到近似 capsule-like representations 的結果
另外提一個不太嚴謹的想法,我認為人在辨識物件大部分時間都是依賴快速、自動化,接近反射的過程,這是後你用上的是估計模型,是一種快速近似;當你便是不出是什麼物體時候,你會停下來思考,甚至轉動你的視角,嘗試去精確估計,這時候你不會使用估計模型,而是專為你眼前的物體重新去估計變量,經過一些思考計算,你可以精確估計出來積木與姿態等等,並也可以在腦海中還原出這個物體,再把估計到的這些變量丟給估計模型去重新訓練,這裡用的就是監督式學習,估計模型看到這樣的物體就應該要估計出怎樣的變量數值,所以兩種快慢的認知模式,是同時存在與交互訓練的
敬啟期待!