序列資料模型我們常用LSTM、或是各種RNN的變形,在主流的各種任務上都取得了非常好的結果,如機器翻譯、序列生成等;但因為遞迴特性,訓練過程很難平行化計算,難以利用硬體加速,此外,RNN模型依然存在記憶遺忘問題,很難捕捉序列的長期關係
近年來出現不少不是基於RNN序列模型,這篇When Recurrent Models Don’t Need to be Recurrent分析兩種模型於序列模型上的差異,非基於RNN模型如之前介紹的Wavenet,是一種Feed-Forward序列生成的模型,本篇要介紹的是Attention Is All You Need,論文名稱很霸氣,果然有實力要叫什麼名字都可以XD,模型完全只使用注意力機制來做序列模型,在機器翻譯任務上,不僅訓練速度快且效果也非常好,很值得來實作的一篇論文;在後續研究上,注意力機制被用在更多的領域上,例如Self-Attention Generative Adversarial Networks,本篇論文也是扮演重要的承先啟後角色
Model Architecture
論文提出模型稱為Transformer,這篇The Illustrated Transformer介紹非常完整,而且還有動畫來說明,強烈建議先看看這篇,本篇文章就稍微偷懶只簡單談一下其中一些細節心得與看法
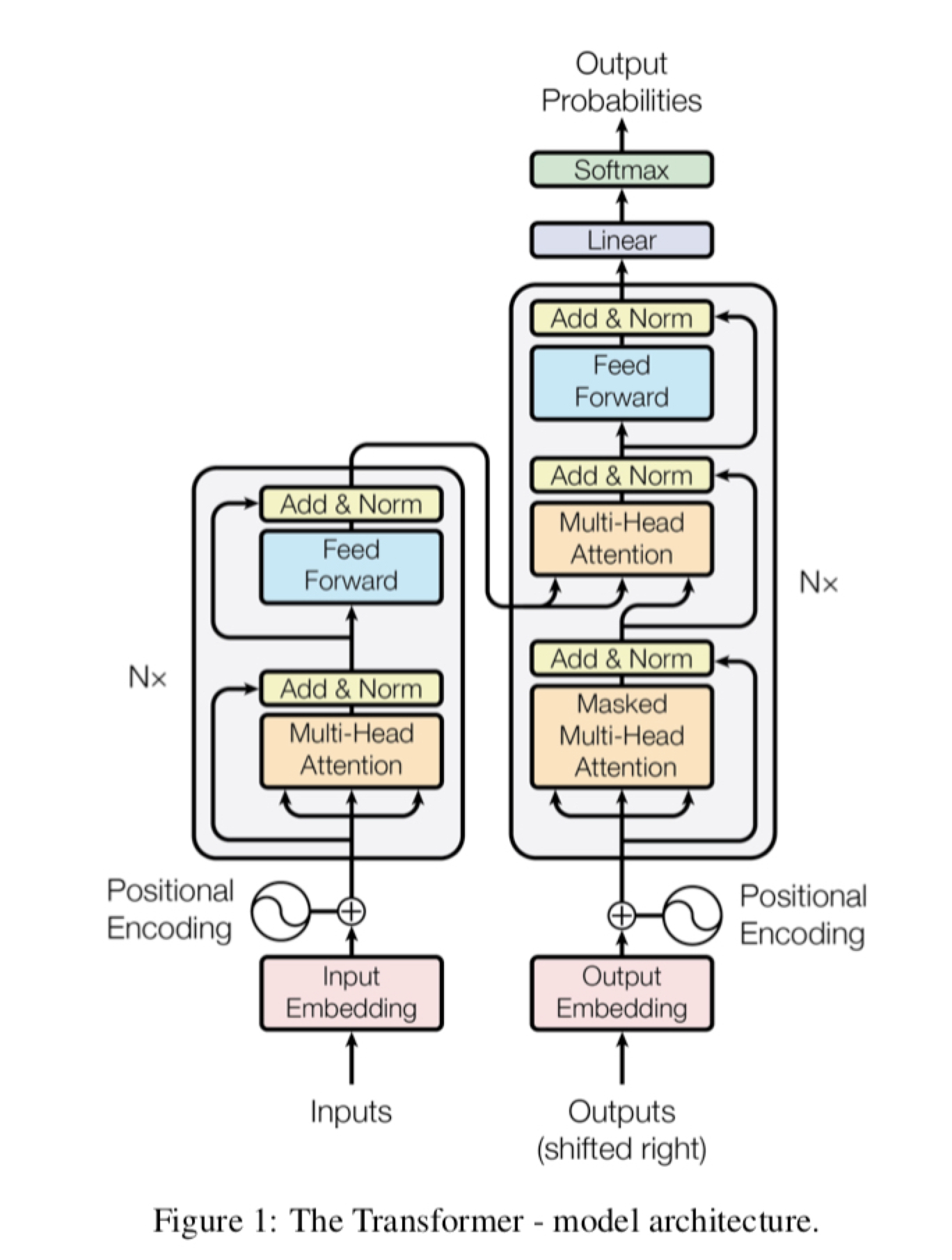
Scaled Dot-Product Attention
注意力機制可以視為類似搜尋的過程,給一個你想搜尋的Query,Query去跟Key做內積看看相近程度,然後用softmax來正規化來得到注意力分佈,最後根據這個注意力分佈來加權Value得到結果,整個過程公式簡單明瞭,僅是矩陣相乘
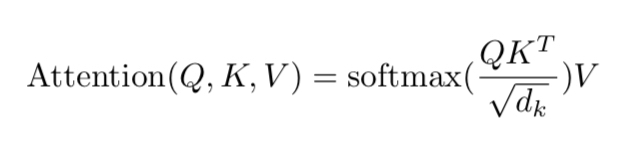
Multi-Head Attention
Multi-Head Attention其實也沒什麼,就只是把Q、K、V分成好幾個部份,然後經過Linear轉換,再將每個部份分別去做Scaled Dot-Product Attention最後黏起來,好處就是讓整個注意力機制過程變得更彈性、可訓練,每個部分可以有不一樣的注意力權重
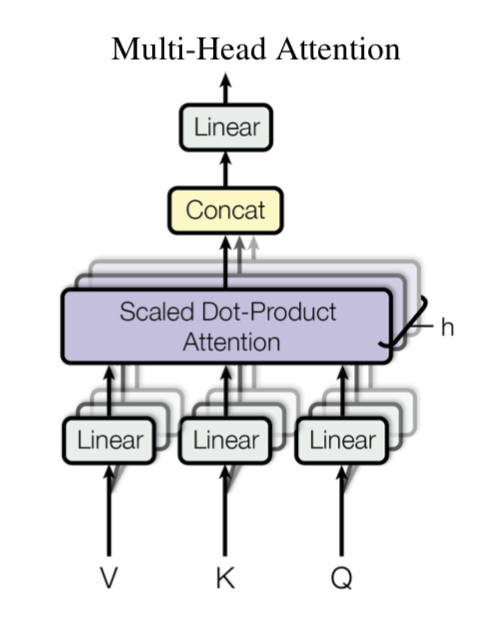
Encoder & Decoder
Encoder與Decoder都是由Block堆疊而成,Block裡面基本上由上一小節介紹的Multi-Head Attention與Feed Forward組成,但是EncoderBlock僅用到Self attention,意思是Multi-Head Attention中的Q,K,V都是同一個輸入
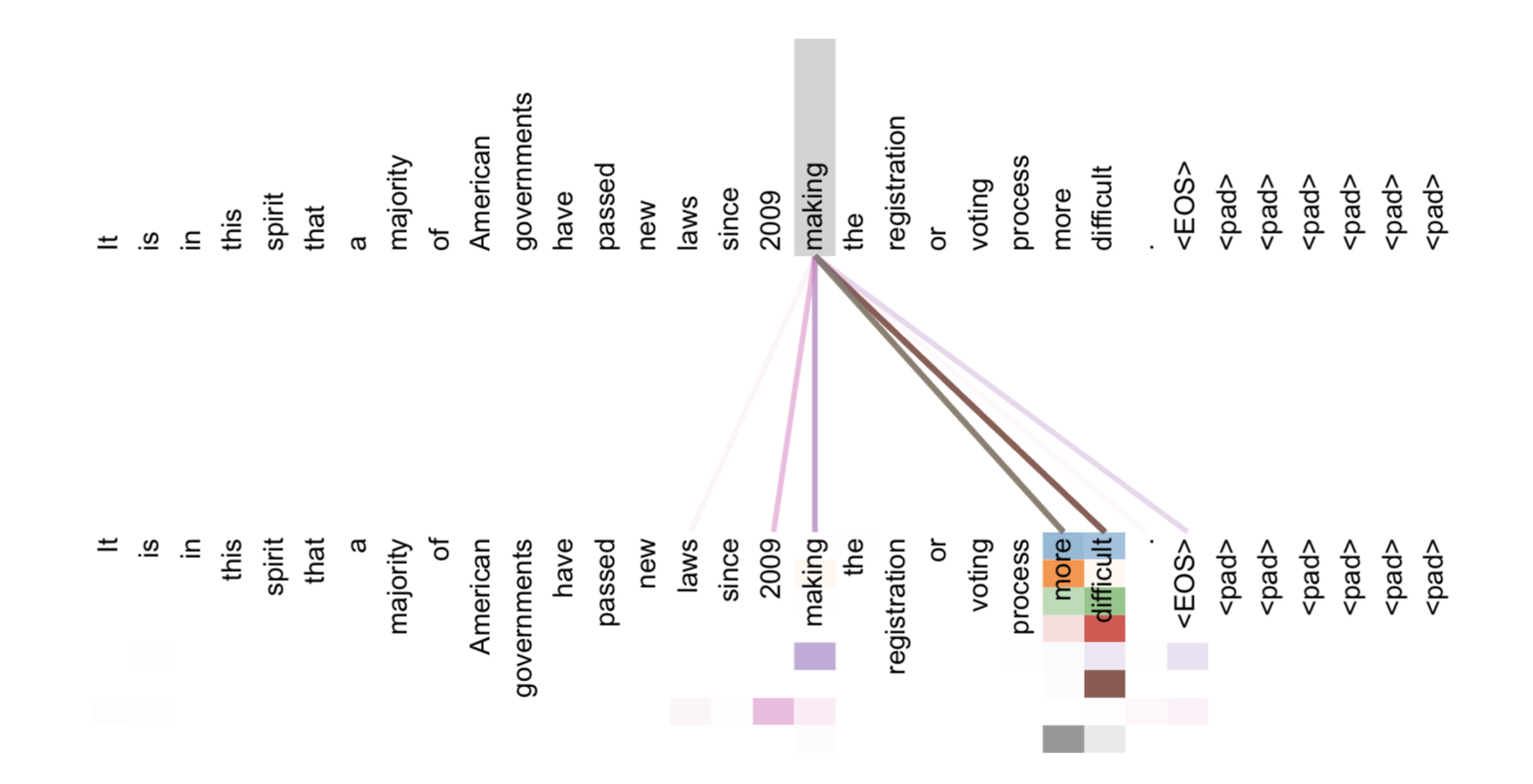
論文裡給了Encoder中5-6層的Attention結果,可以看到Self attention表示了句子中某一個字與其他字之間的關係,且因為是Multi-Head的關係,圖上有不同顏色區分不同部分;Encoder利用Self attention來提取整個序列的結構,且沒有沒有遺忘問題,序列上每個位置都與其他位置考慮到之間關係,計算也相當快速
Decoder在進行解碼時,也先做Self attention來把目標序列的結構考慮進來,然後再引入Encoder的訊息做Multi-Head Attention,最後預測出序列下一個位置
Implement and Tricks
我的實作版本,以pytorch實作並於IWSLT16英文-德語翻譯語料進行訓練與測試
Data preprocessing
把原始資料變成可以訓練的Dataloader常常要花一番苦工,Pytorch提供一系列不同的工具,像是torchvision、torchaudio、torchtext,裡面有一些整理好的資料集或是常用函數,不論是要自己重新做一個新資料集或是直接使用都非常方便,而且減少錯誤機會,所以基本上我不太喜歡自己去重寫資料整理的部分,而是去學習使用已有且穩定的套件
torchtext其實是有直接提供IWSLT16 dataloader使用,但是有些錯誤,所以沒辦法順利直接利用,那只好利用所提供的函數自己來做一個囉
要做一個翻譯的資料集相當簡單,只需要把語料資料整理成兩個文件(也可以是多個,用檔名區分即可)分別對應,像是這樣:
1 | #train.de.txt |
1 | #train.en.txt |
用spacy來做斷詞,並告訴torchtext.data.Field所使用的斷詞器、與相關參數設定
1 | spacy_de = spacy.load('de') |
用torchtext.datasets.TranslationDataset把語料包裝成datasets
1 | train = datasets.TranslationDataset(path='./data/train', |
還有製作字典
1 | DE.build_vocab(train.src, min_freq=3) |
最後就可以包裝成Dataloader了
1 | train_iter = data.BucketIterator(dataset=train, |
以上很簡單介紹用法,這裡還有兩篇(1,2)不錯的教學,大家可以參考
Mask is important
Transformer模型不難理解與實作,但是有個小地方尤其重要,就是輸入需要很仔細地做Mask,非Recurrent模型有個問題,就是輸入長度、大小都必須要是固定的,不管句子長短,要輸入至模型都需要截長補短至固定長度,所以當句子短時候,後面會補上PAD來填滿長度,但是些部分是不能參與至注意力過程的,所以我們每次去做矩陣相成後,需要把某些部分遮起來
1 | output = torch.bmm(Q,K.transpose(1,2)) |
這部分可以配合實作一起看會比較清楚,queries_mask_與keys_mask_是輸入時候給的,告訴模型這個序列的長度資訊,是PAD地方為0其餘為1
既然output是Q,K相乘,我們如果把他們的mask也相乘,就可以得到正確的mask,mask為0的地方代表是PAD去做注意力過程,應該要被忽略
最後用masked_fill來把要忽略的位置填上一個很小的數值,因為masked_fill是把為1的地方填上,所以之前算出來的mask要做反轉,至於為何要填上很小的負數值是因為等一下要做softmax,如果單純填上0,經過softmax可能不為0
Causality is important
Decoder在解碼的時候是基於過去的序列來預測下一個位置,當然不能看到未來的訊息,所以Decoder裡做Self attention要把未來資訊遮蔽,實作上很簡單就是做一個上三角矩陣,但是要保留對角線部分
1 | if self.causality: |
這樣就能保證Decoder訓練過程不會去偷看到下一個位置,只能用自己現在與過去的位置資訊來預測