WaveNet: A Generative Model for Raw Audio 是 DeepMind所提出的一種用於聲音的生成模型,例如最近發布的CLOUD TEXT-TO-SPEECH用的模型架構就是以這個為基礎,還有Making a Neural Synthesizer Instrument裡面都有用上類似WaveNet的結構
Autoregressive model
統計上常用來處理時間序列的方法,用過去歷史資料 $x_{1:t-1}$來預測現在$x_t$,可以看成過去的自己對現在的自己做回歸,所以被稱為自回歸模型
本模型也是用過去的聲音訊號來預測現在的訊號點,這樣的缺點是要生成新樣本的時候效率很差,因為資料有序列關係,總是要等待前面產生,才可以依序產生新的點,算是這類模型的問題
Fully observed model
本模型沒有任何的Latent variable,沒有需要估計或是近似的未知變量,任何資訊都是完全可見的,都是從過去歷史資料來的,這樣的模型架構上更為直接簡單,不需要處理隱變量問題,用上繁瑣的近似演算法等等,而可以直接做MLE訓練
Implement and Tricks
我的實作版本,以Pytorch實作,僅有針對單一人語音訓練,沒有做多人訓練或是TTS等,但實作上相對透明簡單,可以比較深入看看實作過程
Causal & Dilated Conv1d

圖片來源:WaveNet: A Generative Model for Raw Audio
- Causal:不能用到未來的資訊,例如在實作 PixelCNN時,要把Kernel的一部分mask起來,但是在本實作1D conv時,Kernel直接是2,意思為要預測$x_{t}$時,僅用到$x_{t-2}$與$x_{t-1}$,不過要記得把最後一個時間去掉
- Dilated: 讓Kernel看遠一點,不要只看鄰居,如果Dilated設定大一些時,就會看$x_{t}$與$x_{t-N}$,大幅增加視野域,我猜音訊鄰近的時間點值都差不多,不如看遠一點可能會有比較多變化,提供模型更多有用訊息;建議參考這篇來了解Dilated Conv
Residual & Stack block
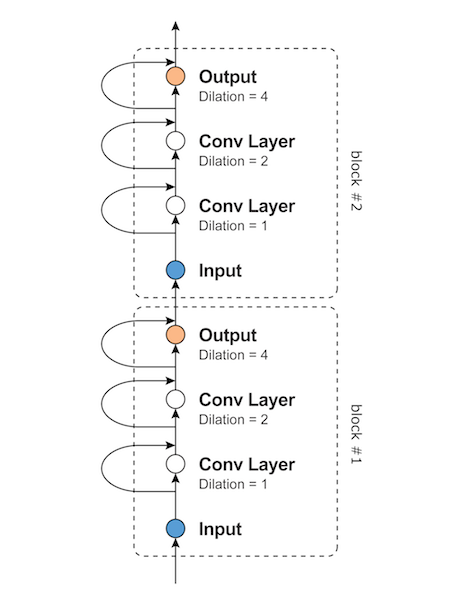
圖片來源:ご注文は機械学習ですか
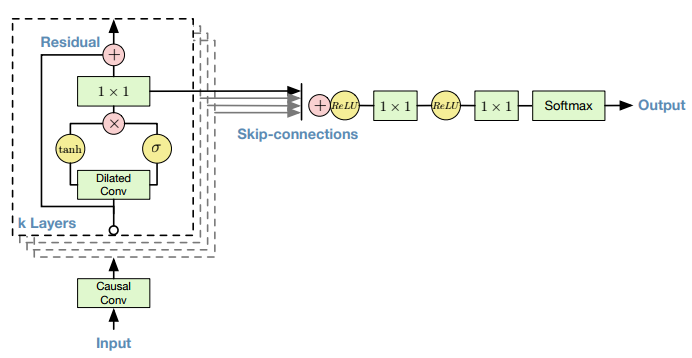
圖片來源:WaveNet: A Generative Model for Raw Audio
- 模型以多個Block堆疊在一起,每個Block含有多個Dilated Conv,並且加入Residual link來幫助梯度傳遞
- 把每一個Block的輸出匯集並加起來,每個Block計算視野不同,越往上層越大,代表資料不同的resolution,最後加總在經過轉換輸出得到下一個時間點的預測
Data processing & Training
- VCTK資料集有多人的語音與文字內容,可以用來訓練TTS系統
- 語音資料處理我用上torchaudio、librosa,但不知道為什麼用兩個套件讀出來的有點差異,我最後用librosa來讀取音訊,還有把無聲部分去掉,這個步驟非常重要!不然訓練到最後只會一直產生靜音,再用torchaudio做Mulaw encoding
- 訓練batch size為1,一次給一段語音來訓練,基本上因為訓練資料長度差異很大,要做padding很浪費與不好做,再且顯卡記憶體也不夠大,所以一次訓練一個語音檔是合理的做法
- 訓練大概要2天,而且頗慢的,建議做learning rate scheduling從0.001往下到0.00001,我訓練在p225這個語音上,最後得到loss約2左右,可以得到還可以的結果
- 計算視野其實蠻簡單,就餵給模型資料來測試看多長的資料,模型剛好輸出為1,就是模型的視野,代表要預測下一個時間點,需要往前看多長的資料
- 產生新樣本非常慢的,請耐心等待,所以這一篇頂多只能說是開一個研究開頭,而且也無法直接做到TTS或其他應用,而是一個好的音訊產生網路結構,後續很多聲音產生都是基於此