基於能量模型(Energy-based model)是一種基於能量函數來定義機率模型的方式,能量函數是用來衡量變數的可能性,為什麼這裡不是說是給出機率呢?因為能量函數的輸出是個實數,能量越小也代表可能性越高,如果要換算成機率就必須要考慮所有的可能性,除上正規化項才能讓這個值符合機率的要求,但求解這個正規化項往往是相當困難的
很多問題其實我們也不用真的去求出正規化項,能量函數已經足夠了,例如分類問題,實際上只需要讓你的目標類別是能量最低的,其他的類別能量提高即可,能量函數的設計相當彈性,所以很多問題其實都可以放入到 EBM 框架裡來解釋,Yann LeCun 大神在最近於 ICLR 2020 也給了個 Keynote 關於 Self-supervised learning 與 EBM 的演講,與YT神人 Yannic Kilcher 線上討論 EBM,還有最近有相當多的基於能量的生成模型,甚至都有超越 GAN 的表現,這經典有點老派的 EBM 最近又熱了起來,趕緊來看看!
Energy-based model
假設我們有一個參數為 $\theta$ 的能量函數 $E_\theta(x)$,將輸入變數$x$輸出一個代表能量的實數,所以可以定義出機率函數為
$$
p_{\boldsymbol{\theta}}(\mathbf{x})=\frac{\exp \left(-E_{\boldsymbol{\theta}}(\mathbf{x})\right)}{Z_{\theta}}
$$
為了要滿足機率的要求,定義正規化項 $Z_\theta$ 為各種可能的 x 下能量的總和
$$
Z_{\boldsymbol{\theta}}=\int \exp \left(-E_{\boldsymbol{\theta}}(\mathbf{x})\right) \mathrm{d} \mathbf{x}
$$
我們可以看到 $Z_\theta$ 是個很難求出的項,因為要把所有 x 的能量都計算出來,在高維度的狀況下是無法被求解的,所以我們需要一些方式來近似或是避免直接去計算 $Z_\theta$
Maximum likelihood training with MCMC
一般來說訓練機率模型的方式就是最大化機率似然值,那我們也來看看如何訓練能量函數的參數$\theta$,來最大化 $p_\theta(x)$,首先來看 $\theta$ 對 $\log p_\theta(x)$ 的梯度如何計算
$$
\nabla_{\boldsymbol{\theta}} \log p_{\boldsymbol{\theta}}(\mathbf{x})=-\nabla_{\boldsymbol{\theta}} E_{\boldsymbol{\theta}}(\mathbf{x})-\nabla_{\boldsymbol{\theta}} \log Z_{\boldsymbol{\theta}}
$$
第一個項就是 $\theta$ 對於能量函數於 x 的梯度,是很容易計算出來的,並沒什麼特別的問題,但第二項我們依然還是有 $Z_\theta$,我們要如何求解 $\nabla_{\boldsymbol{\theta}} \log Z_{\boldsymbol{\theta}}$ 呢?這裡會用上一個計算技巧,計算取 log 的函數 $f$ 的梯度時,可以得到
$$
\nabla_{\theta} \log f(\mathbf{x} ; \theta)=\frac{\nabla_{\theta} f(\mathbf{x} ; \theta)}{f(\mathbf{x} ; \theta)}
$$
應用於 $\nabla_{\boldsymbol{\theta}} \log Z_{\boldsymbol{\theta}}$ 得到
$$
\begin{split}
\nabla_{\boldsymbol{\theta}} \log Z_{\boldsymbol{\theta}}
&= \frac{\nabla_{\boldsymbol{\theta}} Z_{\boldsymbol{\theta}}}{Z_{\boldsymbol{\theta}}} \\
&= \frac{1}{Z_{\boldsymbol{\theta}}} \int \nabla_{\boldsymbol{\theta}} \exp \left(-E_{\boldsymbol{\theta}}(\mathbf{x})\right) d \mathbf{x} \\
&= \int \frac{1}{Z_{\boldsymbol{\theta}}} \exp \left(-E_{\boldsymbol{\theta}}(\mathbf{x}) \right) \left(-\nabla_{\boldsymbol{\theta}} E_{\boldsymbol{\theta}}(\mathbf{x})\right) d \mathbf{x} \\
&= \int \frac{ \exp \left(-E_{\boldsymbol{\theta}}(\mathbf{x})\right) }{Z_{\boldsymbol{\theta}}}\left(-\nabla_{\boldsymbol{\theta}} E_{\boldsymbol{\theta}}(\mathbf{x})\right) d \mathbf{x} \\
&= \int p_{\boldsymbol{\theta}}(x) \left(-\nabla_{\boldsymbol{\theta}} E_{\boldsymbol{\theta}}(\mathbf{x})\right) d \mathbf{x} \\
&= E_{\mathbf{x} \sim p_{\theta}(\mathbf{x})}\left[-\nabla_{\boldsymbol{\theta}} E_{\boldsymbol{\theta}}(\mathbf{x})\right]
\end{split}
$$
第二項變成我們需要從 $p_\theta(x)$ 抽樣出 x 來計算能量函數的梯度,其實這裡跟 GAN 的訓練過程是有點相似的,如果把判別器看成一種能量函數,就是要對資料給低的能量,而對於抽樣的樣本要賦予高的能量,之後也有一些研究是結合 EBM 與 GAN 的模型,有機會後續會跟大家分享;另外值得思考的是很多基於 MLE 訓練的模型,都只有在資料上學習,但是資料並沒有辦法覆蓋整個空間,這裡除了對資料學習外,還需要去抽樣一些可能的樣本,來增強能量函數的估計能力,這個過程也相似於對比學習 Contrastive Learning,訓練過程中引入負樣本來幫助學習到好的表徵
簡單梳理一下,我們最後得到的式子為
$$
\nabla_{\boldsymbol{\theta}} \log p_{\boldsymbol{\theta}}(\mathbf{x})=-\nabla_{\boldsymbol{\theta}} E_{\boldsymbol{\theta}}(\mathbf{x})- E_{\mathbf{x} \sim p_{\theta}(\mathbf{x})}\left[-\nabla_{\boldsymbol{\theta}} E_{\boldsymbol{\theta}}(\mathbf{x})\right]
$$
Implementation
接著我們來嘗試訓練一個 EBM,這次我使用了 Jax 與 Flax 來實作,最明顯的感受是非常快!可以比我用 Pytorch 的版本快50倍,至於其他的好處與心得,應該會另開一篇跟大家分享,基本上他的語法跟 Numpy 是幾乎相同的,應該是不會影響理解
我們先看一些核心的部分,基本上對應著我們剛推導出來的式子,model 就是我們定義的能量函數,分別對資料與抽樣樣本去計算能量,並計算差異與額外的 regularization
1 | def loss(param,data,sample): |
至於如何抽樣出樣本呢?這裡就使用了上一篇介紹的 Langevin Dynamics 抽樣方法,從能量函數中去抽樣出新樣本
1 | def langevin_sampling(key, |
可以看程式中的第9行,是對應 langevin sampling 的公式,這裡還有點小技巧就是有加上退火,所以 step_size 會用來越小,抽樣的效果會好很多
經過訓練後,我們可以看到能量函數有學到資料的分佈(圖有點變形,Colab裡是正常的)
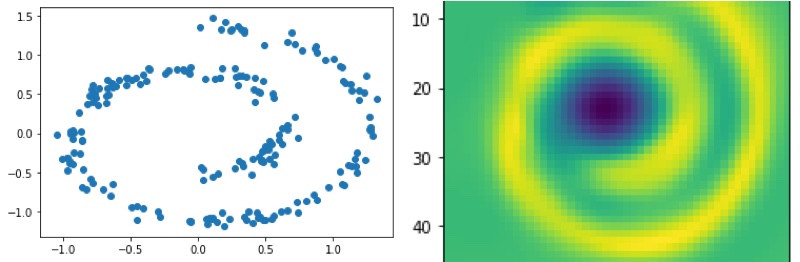
結語
本文章我們了解了 EBM 與如何用 MCMC 方式來訓練,雖然 Langevin Dynamics 已經算是相當快速與好用的一種抽樣方式了,但於更複雜的真實資料可能需要更久的抽樣步數,造成訓練上的難點,而最近相當受到重視的訓練方法為 Score Matching,無需從模型去抽樣來計算梯度,且架構上更適合深度學習模型設計,在影像、三維點雲資料上都有非常驚艷的生成能力,後續我會分享相關的研究,敬請期待!